SQLSERVER2012 列存储索引的简单研究和测试
转自:微软技术大会2016

逐行插入:插入数据-》行组 超过100K 102400行才会插入到压缩行组-》压缩行组-》移动元组-》列段
大批量插入:插入数据 超过100K 102400行-》压缩行组-》移动元组-》列段
数据插入到行组时,一旦并发度过高,会临时生成多个临时行组,临时行组最后会合并为一个行组
插入数据-》行组 (行组会有X锁行锁)影响并发

两种方式
建表时候直接创建一个聚集列存储索引表建表时候先建一个普通聚集索引表,然后在这个普通聚集索引表上建立一个聚集列存储索引(一个聚集索引表变成了两个副本两份数据,一个是聚集索引,一个是聚集列存储索引)SQL2014:聚集列存储索引表不能建立主键,不支持有大对象数据类型nvarchar(max)等的表SQL2016:聚集列存储索引表可以建立主键,支持有大对象数据类型nvarchar(max)等的表
http://mysql.taobao.org/monthly/2017/03/04/
delta store->列存储

看这篇文章之前可以先看一下下面这两篇文章:
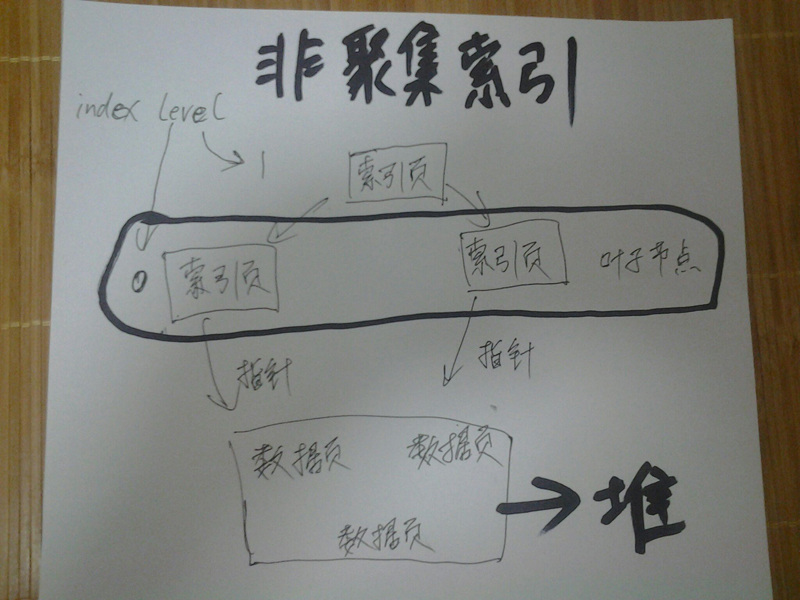
列存储索引
非聚集索引
还有这一篇文章
https://www.sqlpassion.at/archive/2017/01/30/columnstore-segment-elimination/?awt_l=BJCrA&awt_m=3mFjBb8vbIYUUTS
行组-》加密,压缩-》元数据,段-》blob段数据列存储

东方瑞通
一张表水平切为多个行组,各个行组有垂直切为多个段,每个小方块为一个段(一个表又水平切又垂直切成多个小方块(段))
段列中的部分行的一个集合包含相同行的段是一个行组数据以段为单位进行压缩每个段存储在不同lob页中段是IO访问的最小单位

建立测试环境
先创建一张表
1 USE [pratice] 2 GO 3 IF (OBJECT_ID('TestTable') IS NOT NULL) 4 DROP TABLE [dbo].[TestTable] 5 GO 6 CREATE TABLE TestTable 7 ( 8 id INT , 9 c1 INT 10 )11 GO 1 DECLARE @i INT2 SET @i=13 WHILE @i<100014 BEGIN5 INSERT INTO TestTable (id,c1)6 SELECT @i,@i7 SET @i=@i+18 END9 GO
1 SELECT COUNT(*) FROM TestTable2 SELECT TOP 10 * from TestTable
在C1列上创建一个列存储索引
1 CREATE NONCLUSTERED columnstore INDEX PK__TestTable__ColumnStore ON TestTable(c1)
执行计划
在上面给出的文章里提到
下面几个SQL语句的执行计划也显示出列存储索引不会seek
(2)列存储索引不支持 SEEK
如果查询应返回行的一小部分,则优化器不大可能选择列存储索引(例如:needle-in-the-haystack 类型查询)。
如果使用表提示 FORCESEEK,则优化器将不考虑列存储索引。
1 SELECT * FROM TestTable WHERE [C1]=60 --列存储索引扫描 RID查找2 SELECT id FROM TestTable WHERE [C1]=60 --列存储索引扫描 RID查找3 SELECT c1 FROM TestTable WHERE [C1]=60 --列存储索引扫描4 SELECT * FROM TestTable WHERE id=60 --全表扫描5 SELECT c1 FROM TestTable --列存储索引扫描6 SELECT * FROM TestTable --全表扫描

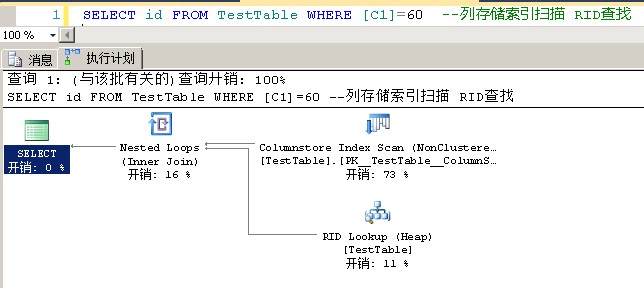
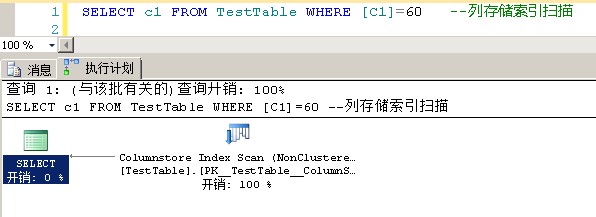



列存储索引的结构
先创建一张表保存DBCC的结果


1 USE [pratice] 2 GO 3 CREATE TABLE DBCCResult ( 4 PageFID NVARCHAR(200), 5 PagePID NVARCHAR(200), 6 IAMFID NVARCHAR(200), 7 IAMPID NVARCHAR(200), 8 ObjectID NVARCHAR(200), 9 IndexID NVARCHAR(200),10 PartitionNumber NVARCHAR(200),11 PartitionID NVARCHAR(200),12 iam_chain_type NVARCHAR(200),13 PageType NVARCHAR(200),14 IndexLevel NVARCHAR(200),15 NextPageFID NVARCHAR(200),16 NextPagePID NVARCHAR(200),17 PrevPageFID NVARCHAR(200),18 PrevPagePID NVARCHAR(200)19 )
我们看一下列存储索引在表中建立了一些什么页面
1 --TRUNCATE TABLE [dbo].[DBCCResult]2 INSERT INTO DBCCResult EXEC ('DBCC IND(pratice,TestTable,-1) ')3 4 SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC 先说明一下:DBCC IND的结果
PageType 页面类型:1:数据页面;2:索引页面;3:Lob_mixed_page;4:Lob_tree_page;10:IAM页面IndexID 索引ID:0 代表堆, 1 代表聚集索引, 2-250 代表非聚集索引 大于250就是text或image字段
由于表中的页面太多,本来想truncate table并只插入1000行记录到表,让大家看清楚一下表中的页面的,但是遇到下面错误

文章中里提到:
(14).有列存储索引后,表变成只读表,不能进行添加,删除,编辑的操作。 insert into TestTable(c1,c2) select rand(),rand() 错误信息是这样的:由于不能在包含列存储索引的表中更新数据,INSERT 语句失败。
微软提供了三种方式来解决这个问题,这里简单介绍两种: 1) 若要更新具有列存储索引的表,先删除列存储索引,执行任何所需的 INSERT、DELETE、UPDATE 或 MERGE 操作,然后重新生成列存储索引。
2) 对表进行分区并切换分区。对于大容量插入,先将数据插入到一个临时表中,在临时表上生成列存储索引,然后将此临时表切换到空分区。对于其他更新,将主表外的一个分区切换到一个临时表中,禁用或删除临时表上的列存储索引,执行更新操作,在临时表上重新生成或重新创建列存储索引,然后将临时表切换回主表。
只能够先删除列存储索引,再truncate table了
1 DROP INDEX PK__TestTable__ColumnStore ON TestTable
truncate table,再插入1000条记录,重新建立列存储索引,看到DBCC IND的结果如下:
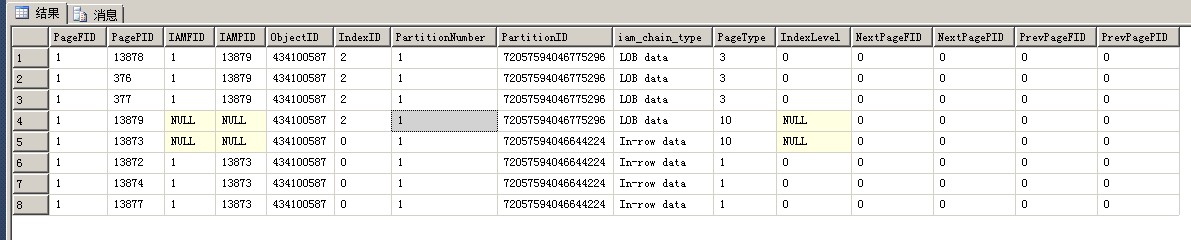
表中有10000条记录的话,表中的页面类型又增加了一种,而且可以看到,列存储索引的表中是没有索引页面的,只有LOB页面
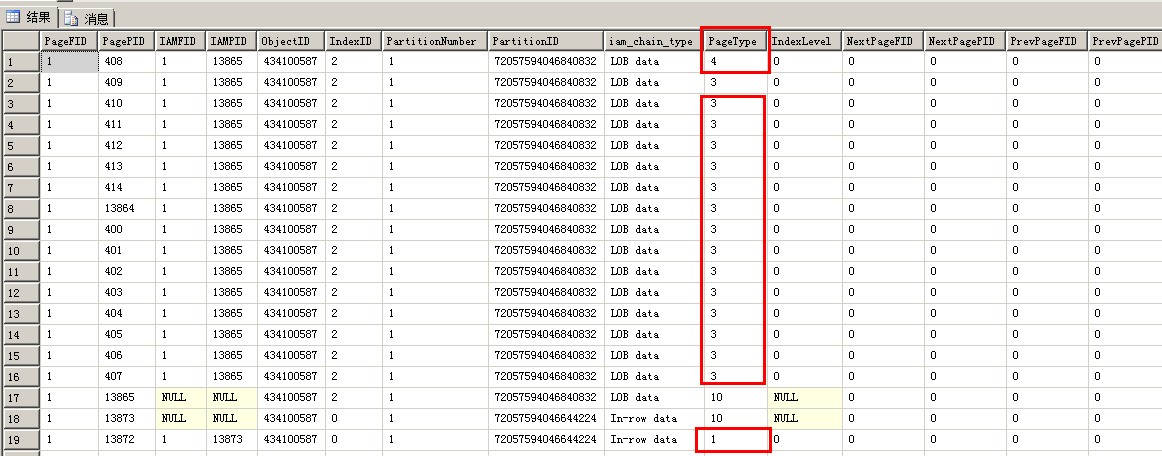
10000条记录的表比1000条记录的表多了一种页面类型:Lob_tree_page
为了避免篇幅过长,有关Lob_tree_page页面的详细内容请看我的另一篇文章
这里为什麽要用LOB页来存放索引数据呢?
本人认为因为要将数据转为二进制并压缩,所以用LOB页来存放索引数据
测试和比较
下面建立一张非聚集索引表
1 USE [pratice] 2 GO 3 4 CREATE TABLE TestTable2 5 ( 6 id INT , 7 c1 INT , 8 c2 INT 9 )10 11 CREATE NONCLUSTERED INDEX NCL__TestTabl__C1 ON TestTable2(c1)12 13 DECLARE @i INT14 SET @i=115 WHILE @i<1000116 BEGIN17 INSERT INTO TestTable2 (id,c1)18 SELECT @i,@i19 SET @i=@i+120 END21 22 SELECT COUNT(*) FROM TestTable223 SELECT TOP 10 * from TestTable2
为什么用非聚集索引表来比较?
大家可以看一下列存储索引的建立语句
1 CREATE NONCLUSTERED columnstore INDEX PK__TestTable__ColumnStore ON TestTable(c1)
在非聚集索引上加多了一个columnstore关键字
而且列存储索引的表的页面情况跟非聚集索引表的页面情况几乎是一样的
除了LOB页面,数据页面还是在堆里面的

测试结果:
1 SET NOCOUNT ON 2 SET STATISTICS IO ON 3 SET STATISTICS TIME ON 4 SELECT id FROM TestTable WHERE [C1]=60 --列存储索引扫描 RID查找 5 SQL Server 分析和编译时间: 6 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 7 表 'TestTable'。扫描计数 1,逻辑读取 37 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 8 9 SQL Server 执行时间:10 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。11 -------------------------------------------------------------12 SET NOCOUNT ON 13 SET STATISTICS IO ON14 SET STATISTICS TIME ON15 SELECT id FROM TestTable2 WHERE [C1]=60 --索引查找 RID查找16 SQL Server 分析和编译时间: 17 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。18 表 'TestTable2'。扫描计数 1,逻辑读取 3 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。19 20 SQL Server 执行时间:21 CPU 时间 = 15 毫秒,占用时间 = 17 毫秒。22 ----------------------------------------------------------------------------------
CPU执行时间非聚集索引要多一些
而逻辑读取非聚集索引表比列存储索引表少了37-3=34次
因为非聚集索引使用的是索引查找,找到索引页就可以了,而列存储索引还要扫描LOB页面
----------------------------------------------------------------------------------
上面是没有清空数据缓存和执行计划缓存的情况下的测试结果
下面是清空了数据缓存和执行计划缓存的情况下的测试结果
1 USE [pratice] 2 GO 3 DBCC DROPCLEANBUFFERS 4 DBCC freeproccache 5 GO 6 SET NOCOUNT ON 7 SET STATISTICS IO ON 8 SET STATISTICS TIME ON 9 SELECT id FROM TestTable2 WHERE [C1]=60 --索引查找 RID查找10 11 12 SQL Server 分析和编译时间: 13 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。14 15 SQL Server 执行时间:16 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。17 SQL Server 分析和编译时间: 18 CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。19 DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。20 21 SQL Server 执行时间:22 CPU 时间 = 0 毫秒,占用时间 = 2 毫秒。23 DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。24 25 SQL Server 执行时间:26 CPU 时间 = 0 毫秒,占用时间 = 18 毫秒。27 SQL Server 分析和编译时间: 28 CPU 时间 = 63 毫秒,占用时间 = 95 毫秒。29 30 SQL Server 执行时间:31 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。32 33 SQL Server 执行时间:34 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。35 36 SQL Server 执行时间:37 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。38 SQL Server 分析和编译时间: 39 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。40 表 'TestTable2'。扫描计数 1,逻辑读取 28 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。41 42 SQL Server 执行时间:43 CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。44 ---------------------------------------------------------------------45 USE [pratice]46 GO47 DBCC DROPCLEANBUFFERS48 DBCC freeproccache49 GO50 SET NOCOUNT ON 51 SET STATISTICS IO ON52 SET STATISTICS TIME ON53 SELECT id FROM TestTable WHERE [C1]=60 --列存储索引扫描 RID查找54 55 SQL Server 分析和编译时间: 56 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。57 58 SQL Server 执行时间:59 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。60 SQL Server 分析和编译时间: 61 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。62 DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。63 64 SQL Server 执行时间:65 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。66 DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。67 68 SQL Server 执行时间:69 CPU 时间 = 0 毫秒,占用时间 = 13 毫秒。70 SQL Server 分析和编译时间: 71 CPU 时间 = 0 毫秒,占用时间 = 26 毫秒。72 73 SQL Server 执行时间:74 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。75 76 SQL Server 执行时间:77 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。78 79 SQL Server 执行时间:80 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。81 SQL Server 分析和编译时间: 82 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。83 表 'TestTable'。扫描计数 1,逻辑读取 40 次,物理读取 1 次,预读 68 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。84 85 SQL Server 执行时间:86 CPU 时间 = 0 毫秒,占用时间 = 41 毫秒。
可以看到列存储索在执行时间上占优势,但是在IO上比非聚集索引差一点点
列存储索引所申请的锁
1 USE [pratice] 2 GO 3 SET TRANSACTION ISOLATION LEVEL REPEATABLE READ 4 GO 5 6 BEGIN TRAN 7 SELECT id FROM TestTable WHERE [C1]=60 --列存储索引扫描 RID查找 8 9 --COMMIT TRAN10 11 USE [pratice] --要查询申请锁的数据库12 GO13 SELECT14 [request_session_id],15 c.[program_name],16 DB_NAME(c.[dbid]) AS dbname,17 [resource_type],18 [request_status],19 [request_mode],20 [resource_description],OBJECT_NAME(p.[object_id]) AS objectname,21 p.[index_id]22 FROM sys.[dm_tran_locks] AS a LEFT JOIN sys.[partitions] AS p23 ON a.[resource_associated_entity_id]=p.[hobt_id]24 LEFT JOIN sys.[sysprocesses] AS c ON a.[request_session_id]=c.[spid]25 WHERE c.[dbid]=DB_ID('pratice') AND a.[request_session_id]=@@SPID ----要查询申请锁的数据库26 ORDER BY [request_session_id],[resource_type] 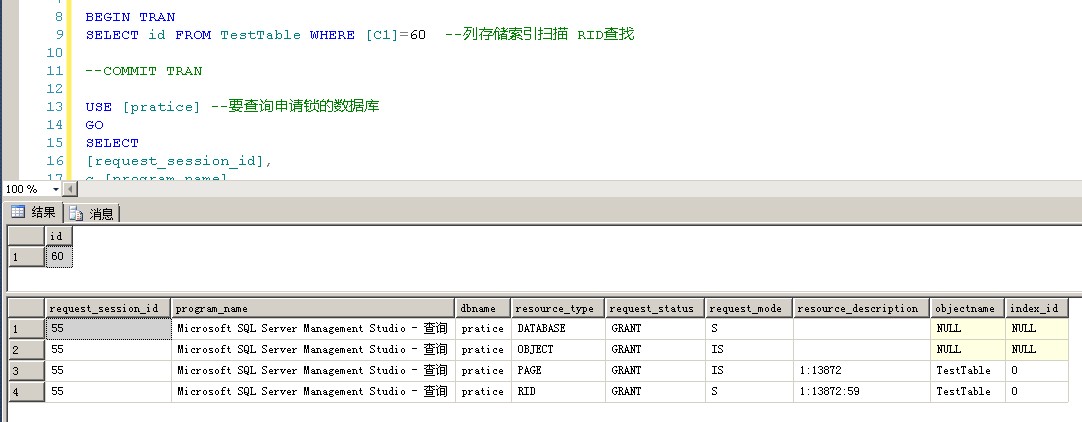

可以看到虽然是列存储索引扫描,但是也没有在LOB页面申请锁,只是在普通数据页面和真正的数据行上申请了锁
使用列存储索引,阻塞的机会也减少了
SQL Server 2012列存储索引技术(云栖社区)
https://yq.aliyun.com/articles/69254?spm=5176.100240.searchblog.59.hrBlST#
Batch Mode Processing 是SQL Server新的查询处理算法,专门设计来高效地处理大量数据的批处理算法,以加快统计分析类查询的效率。其实这个算法的原理实现非常简单,SQL Server有一个专门的系统视图sys.column_store_segments来存放列存储索引的每个列的每个Segments的最小值和最大值,当SQL Server执行Batch Mode Processing查询时,只需要和查询筛选条件对比,
就可以知道对应的Segment是否包含满足条件的数据,从而可以实现快速的跳过哪些不满足条件的Segment由于每个Segment中包含成千上万条记录,所以SQL Server筛选出满足条件的效率非常高,因此大大节约了磁盘I/O和因此带来的CPU开销。这种跳过不满足条件Segment的算法专业术语叫Segment Elimination。Segment Elimination的做法:一个传统聚集索引表,用drop_exist的方式创建聚集列存储索引并用查询提示maxdop=1
https://www.sqlpassion.at/archive/2017/01/30/columnstore-segment-elimination/?awt_l=BJCrA&awt_m=3ZdebPPtXEYUUTS
SET STATISTICS IO ON
能看到 Segment skipped 的数量
-- Now we create a traditional RowStore Clustered Index to sort our-- table data by the column "DateKey".CREATE CLUSTERED INDEX idx_ci ON FactOnlineSales_Temp(DateKey)GO -- "Swap" the Clustered Index through a Clustered ColumnStore IndexCREATE CLUSTERED COLUMNSTORE INDEX idx_ci ON FactOnlineSales_TempWITH (DROP_EXISTING = ON)GO
CREATE CLUSTERED COLUMNSTORE INDEX idx_ci ON FactOnlineSales_TempWITH (DROP_EXISTING = ON, MAXDOP = 1)GO
--查询列存储的压缩方式USE ColumnStoreDBGOSELECT DISTINCTtable_name = object_name(part.object_id),ix.name,part.data_compression_desc FROM sys.partitions as partINNER JOIN sys.indexes as ixON part.object_id = ix.object_idAND part.index_id = ix.index_idWHERE part.object_id = object_id('dbo.SalesOrder','U')AND ix.name = 'NCSIX_ALL_Columns'
--查询每个列存储段的最大值和最小值USE ColumnStoreDBGOSELECT table_name = object_name(part.object_id),col.name,seg.segment_id,seg.min_data_id,seg.max_data_id,seg.row_countFROM sys.partitions as partINNER JOIN sys.column_store_segments as segON part.partition_id = seg.partition_idINNER JOIN sys.columns as colON part.object_id = col.object_idAND seg.column_id = col.column_idWHERE part.object_id = object_id('dbo.SalesOrder','U')AND seg.column_id = 1ORDER BY seg.segment_id row mode改为 batch mode
INNER JOIN使用Batch Mode而OUTER JOIN使用Row Mode-- Batch mode processing will be used when INNER JOINSELECT at.Model ,TotalAmount = SUM(ord.UnitPrice) ,TotalQty = SUM(ord.OrderQty)FROM dbo.AutoType AS at INNER JOIN dbo.SalesOrder AS ord ON ord.AutoID = at.AutoIDGROUP BY at.Model-- OUTER JOIN workaround;WITH intermediateDataAS( SELECT at.AutoID ,TotalAmount = SUM(ord.UnitPrice) ,TotalQty = SUM(ord.OrderQty) FROM dbo.AutoType AS at INNER JOIN dbo.SalesOrder AS ord ON ord.AutoID = at.AutoID GROUP BY at.AutoID)SELECT at.Model ,TotalAmount = ISNULL(itm.TotalAmount, 0) ,TotalQty = ISNULL(itm.TotalQty, 0)FROM dbo.AutoType AS at LEFT OUTER JOIN intermediateData AS itm ON itm.AutoID = at.AutoIDORDER BY itm.TotalAmount DESC-------------------------------------------------------------IN & EXISTS使用Row Mode-- DEMO 2: IN & EXISTS both use row mode processingIF OBJECT_ID('dbo.HondaAutoTypes', 'U') IS NOT NULLBEGIN TRUNCATE TABLE dbo.HondaAutoTypes DROP TABLE dbo.HondaAutoTypesENDSELECT * INTO dbo.HondaAutoTypesFROM dbo.AutoTypeWHERE make = 'Honda'-- IN use row modeSELECT OrderDay = CONVERT(CHAR(10), ord.OrderDate, 120) ,TotalAmount = SUM(ord.UnitPrice) ,TotalQty = SUM(ord.OrderQty)FROM dbo.SalesOrder AS ordWHERE ord.AutoID IN(SELECT AutoID FROM dbo.HondaAutoTypes)GROUP BY CONVERT(CHAR(10), ord.OrderDate, 120)ORDER BY 1 DESC-- EXISTS use row mode too.SELECT OrderDay = CONVERT(CHAR(10), ord.OrderDate, 120) ,TotalAmount = SUM(ord.UnitPrice) ,TotalQty = SUM(ord.OrderQty)FROM dbo.SalesOrder AS ordWHERE EXISTS(SELECT TOP 1 * FROM dbo.HondaAutoTypes WHERE AutoID = ord.AutoID)GROUP BY CONVERT(CHAR(10), ord.OrderDate, 120)ORDER BY 1 DESC-- IN & EXISTS workaround using INNER JOINSELECT OrderDay = CONVERT(CHAR(10), ord.OrderDate, 120) ,TotalAmount = SUM(ord.UnitPrice) ,TotalQty = SUM(ord.OrderQty)FROM dbo.SalesOrder AS ord INNER JOIN dbo.HondaAutoTypes AS hat ON ord.AutoID = hat.AutoIDGROUP BY CONVERT(CHAR(10), ord.OrderDate, 120)ORDER BY 1 DESC-- or we also can use IN( ) to make it use batch mode.SELECT OrderDay = CONVERT(CHAR(10), ord.OrderDate, 120) ,TotalAmount = SUM(ord.UnitPrice) ,TotalQty = SUM(ord.OrderQty)FROM dbo.SalesOrder AS ordWHERE ord.AutoID IN(104,106)GROUP BY CONVERT(CHAR(10), ord.OrderDate, 120)ORDER BY 1 DESC-------------------------------------------------------------UNION ALL-- DEMO 3: UNION ALL usually use row modeIF OBJECT_ID('dbo.partSalesOrder', 'U') IS NOT NULLBEGIN TRUNCATE TABLE dbo.partSalesOrder DROP TABLE dbo.partSalesOrderENDSELECT TOP 100 * INTO dbo.partSalesOrderFROM dbo.SalesOrderWHERE OrderID < 2500000;-- UNION ALL mostly use row mode;WITH unionSalesOrderAS( SELECT * FROM dbo.SalesOrder AS ord UNION ALL SELECT * FROM dbo.partSalesOrder AS pord)SELECT OrderDay = CONVERT(CHAR(10), ord.OrderDate, 120) ,TotalAmount = SUM(ord.UnitPrice) ,TotalQty = SUM(ord.OrderQty)FROM dbo.AutoType AS at INNER JOIN unionSalesOrder AS ord ON ord.AutoID = at.AutoIDGROUP BY CONVERT(CHAR(10), ord.OrderDate, 120)ORDER BY 1 DESC-- UNION ALL workaround;WITH unionSaleOrdersAS( SELECT OrderDay = CONVERT(CHAR(10), ord.OrderDate, 120) ,TotalAmount = SUM(ord.UnitPrice) ,TotalQty = SUM(ord.OrderQty) FROM dbo.AutoType AS at INNER JOIN SalesOrder AS ord ON ord.AutoID = at.AutoID GROUP BY CONVERT(CHAR(10), ord.OrderDate, 120)), unionPartSaleOrdersAS( SELECT OrderDay = CONVERT(CHAR(10), ord.OrderDate, 120) ,TotalAmount = SUM(ord.UnitPrice) ,TotalQty = SUM(ord.OrderQty) FROM dbo.AutoType AS at INNER JOIN dbo.partSalesOrder AS ord ON ord.AutoID = at.AutoID GROUP BY CONVERT(CHAR(10), ord.OrderDate, 120)), unionAllDataAS( SELECT * FROM unionSaleOrders UNION ALL SELECT * FROM unionPartSaleOrders)SELECT OrderDay ,TotalAmount = SUM(TotalAmount) ,TotalQty = SUM(TotalQty)FROM unionAllDataGROUP BY OrderDayORDER BY OrderDay DESC-------------------------------------------------------------Scalar Aggregates-- DEMO 4: Scalar AggregatesSELECT COUNT(*)FROM dbo.SalesOrder-- workaround ;WITH salesOrderByAutoId([AutoID], cnt)AS( SELECT [AutoID], count(*) FROM dbo.SalesOrder GROUP BY [AutoID])SELECT SUM(cnt)FROM salesOrderByAutoId-- END DEMO 4-------------------------------------------------------------Multiple DISTINCT Aggregates-- DEMO 5: Multiple DISTINCT AggregatesSELECT OrderDay = CONVERT(CHAR(10), ord.OrderDate, 120) ,AutoIdCount = COUNT(DISTINCT ord.[AutoID]) ,UserIdCount = COUNT(DISTINCT ord.[UserID])FROM dbo.AutoType AS at INNER JOIN dbo.SalesOrder AS ord ON ord.AutoID = at.AutoIDGROUP BY CONVERT(CHAR(10), ord.OrderDate, 120)-- workaround;WITH autoIdsCount(orderDay, AutoIdCount)AS( SELECT OrderDay = CONVERT(CHAR(10), ord.OrderDate, 120) ,AutoIdCount = COUNT(DISTINCT ord.[AutoID]) FROM dbo.AutoType AS at INNER JOIN dbo.SalesOrder AS ord ON ord.AutoID = at.AutoID GROUP BY CONVERT(CHAR(10), ord.OrderDate, 120)), userIdsCount(orderDay, UserIdCount)AS( SELECT OrderDay = CONVERT(CHAR(10), ord.OrderDate, 120) ,UserIdCount = COUNT(DISTINCT ord.[UserID]) FROM dbo.AutoType AS at INNER JOIN dbo.SalesOrder AS ord ON ord.AutoID = at.AutoID GROUP BY CONVERT(CHAR(10), ord.OrderDate, 120))SELECT auto.orderDay ,auto.AutoIdCount ,ur.UserIdCountFROM autoIdsCount AS auto INNER JOIN userIdsCount AS ur ON auto.orderDay = ur.orderDay-- END DEMO 5
最后,如有不对的地方,欢迎大家拍砖哦o(∩_∩)o